1905 movie network feature With the go LIVE of "Little Joy", after three years, the "Tongyuan CP" composed of Haiqing and Huang Lei successfully swiped the screen again.
Douban scored 8.0, surpassing the 7.8 score of the previous "Little Separation", which is expected to once again set off a wave of national discussions on family relations and children’s education, and this wave of discussions may not be limited to domestic borders.

On June 7 last year, the sister installment of "Little Joy", "Little Separation", was broadcast on the prime channel of the Mongolian ASIAN BOX film and television channel, surpassing many Korean and American dramas to reach the top of the audience rating list. The educational topics reflected in the series not only hit the "pain points" of Chinese families, but also resonated with Mongolian audiences.
The upcoming word-of-mouth drama "Twelve Hours in Changan" has also successfully "gone overseas" to Japan, Singapore, Malaysia, Brunei, Vietnam and other countries, and has also been launched in North America in the form of "paid content" on online platforms such as Viki, Amazon, and Youtube. This is the first time that domestic dramas going overseas have entered the monthly subscription payment area and achieved quasi-simultaneous playback at home and abroad.

"Twelve Hours in Chang’an" overseas poster
Now,"Chinese dramas go overseas" – the overseas distribution of high-quality domestic dramas has become the norm, not only with more diverse genres and themes, but also with expanding international influence.
From the "Journey to the West" of that year to the current "Twelve Hours in Chang’an", what new trends have been shown in "national dramas going to sea", and what new requirements have been put forward for creators and propagandists?
The types of subject matter are becoming increasingly diverse "National drama going to sea" has become the norm
The history of "Chinese dramas going to sea" has a long history. Early classic costume dramas such as "Journey to the West", "Romance of the Three Kingdoms", "Kangxi Dynasty" and "Huanzhu Gege" can be regarded as the first echelon.
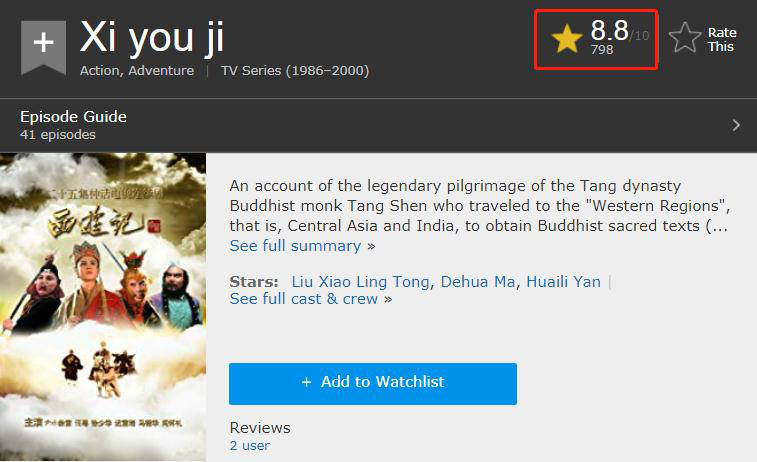
The 86 version of "Journey to the West" was first popular in South East Asia countries such as Myanmar, Vietnam, and Thailand. It has a score of 8.8 on the foreign film review website IMDB, and is still discussed by overseas audiences. Historical dramas such as "Romance of the Three Kingdoms" and "Kangxi Dynasty" have been very popular in Japan and have been rebroadcast on Japanese TV many times.
In 2010, "The Beautiful Times of Daughter-in-law" was "exported" to Tanzania, causing a heated debate. Later, more than 40 domestic dramas such as "Struggle", "My Youth", "Beijing Youth" and "Durala’s Promotion" were also translated into local languages and broadcast in 46 countries including Kenya, Egypt and Zambia.The theme and genre of "Chinese drama going overseas" began to be not limited to costume dramas, and urban emotional dramas could also have a place.
In 2015, "Empresses in the Palace" officially landed on the international streaming platform Netflix, becoming the first domestic drama to be paid to be broadcast on the platform. It is considered a milestone event in the history of "national dramas going overseas".

"The Beautiful Times of Daughter-in-law" "Langya Bang" "Empresses in the palace" Overseas Edition Poster
In 2018, three high-reputation online dramas, including "White Night Chasing the Murderer", "River God" and "Undocumented Crime", went overseas one after another, creating a precedent for the export of domestic online dramas. The recent "Twelve Hours in Changan" has also achieved quasi-simultaneous broadcast on overseas platforms and domestic online platforms on the basis of "paid" broadcast.
In the early 1990s, the overseas marketing of domestic dramas was mostly concentrated in more than 10 countries and regions such as South East Asia, Japan and South Korea. Today, the export of domestic dramas has spread to more than 100 countries and regions.

According to Zhang Lina, editor-in-chief of Alibaba Entertainment Youku, Youku has sent more than 50 copyrighted content overseas in the past two years, and in the first half of 2019 alone, there were nearly 10. "Going overseas has become the norm."
It is not difficult to see from the above example thatDifferent countries and regions have different preferences for domestic drama genres and themes.
From 2013 began to test the waters of domestic drama overseas distribution, there are "Langya Bang", "choose heaven", "love" and other more than 500 episodes overseas distribution experience of Century Youyou company overseas distribution director Zhang Chunlan told Xiaodian Jun, in Japan, South Korea and South East Asia, costume drama, life drama affected by geographical factors, a high degree of acceptance; while in North America, suspense detective theme is very popular.

Century Youyou was responsible for the overseas distribution of "Love"
"Chinese kung fu and ancient martial arts have always been popular in overseas markets, but with the increasing number of Chinese dramas going overseas, the types are becoming more diverse, and some overseas audiences have also developed the habit of chasing Chinese dramas. Sweet pet love dramas and modern suspense dramas are also becoming more and more popular. The current upsurge in realistic themes in the drama market will also play a positive role in the development of overseas audiences," Zhang Chunlan said.
Balancing Chinese stories with global expression Reality themes will see an upsurge
The 30-year journey of Chinese opera going overseas has accumulated and cultivated a large number of overseas fans, and has also continued to expand the overseas influence of Chinese culture. However, in the midst of a boom, "Chinese opera going overseas" still faces some difficulties.
The main export markets of domestic film and television dramas are still concentrated in South East Asia and Chinese-speaking regions, and overseas Chinese are still one of the most important audience groups.
The price of a single episode exported from China is still relatively low, and the lead drama is only a few tens of thousands of dollars per episode. Producer Tang Lijun has revealed that in the Japanese market, the price of a single episode of an American drama may reach 1 million US dollars, a Korean drama may be 200,000 US dollars, and a Chinese drama may sell well for tens of thousands of dollars.

Japanese version of "Hua Qiangu" promotional video Flower
There are many reasons for these difficulties. First, "the current problems in overseas distribution are mainly caused by differences in language and culture." Zhang Chunlan analyzed.
Due to its geographical relationship and cultural proximity, Asia has a close relationship with Chinese culture, making it a natural main market. However, mainstream audiences in Europe, America and other regions are still relatively unfamiliar with Chinese culture, and their language and cultural barriers are relatively high.
In addition,The viewing habits of overseas audiences are also different from those of domestic Chinese audiences.Foreign audiences are more inclined to small-scale works of about 20 to 30 episodes per season, and China’s 70 to 80-episode volume and relatively slow narrative rhythm will inevitably appear "acclimatized" in the process of overseas distribution.
Take "Empresses in the Palace" as an example. When Netflix launched, not only did the length of the original 76 episodes be reduced to 6 episodes, each episode was 90 minutes. The lines lost their original charm after translation.

In the end, the word-of-mouth Chinese drama with a score of 9.1 on Douban only received a 2.5-star review on Netflix. The large number of classical Chinese lines in "Twelve Hours of Changan" also posed no small challenge to translation.

The reason why suspense dramas produced by online platforms such as "White Night Chasing" and "Crime Without a Certificate" are favored by Netflix is precisely because they refer to the shooting techniques and narrative rhythm of American dramas in the script, shooting and editing stages, and are relatively close to the viewing habits of overseas audiences.
In the comments of "Twelve Hours of Chang’an", "fast pace" and "large amount of information" have also become the keywords of many foreign audiences.

At this year’s Shanghai TV Festival "National Drama Going Overseas" related theme forum, Fu Binxing, president of Huace Film Company, said:Whether to use editors who understand local needs, accurate translation and localized promotion and marketing will all affect the quality of Chinese dramas "going global".
In addition to the above points,The quality of the series is still the core factor that affects the success of the overseas distribution of domestic dramas.Whether it is the early "Huanzhu Gege", "Journey to the West" or the recent "Langya List", "White Night Chasing", "Changan Twelve Hours" and other dramas, the success of "going to sea" is backed by excellent production standards.
The current hit "Twelve Hours in Changan" Douban scored as high as 8.6 points, and it also reached 9.5 points after the launch of the overseas video platform viki.

The series is quite elegant from the story, lines to the service of the Tao, focusing on the "Tang style ancient rhyme", and the shooting method and narrative rhythm are very international. The use of "long shots" is quite skilled, and the suspense action elements are also very suitable for overseas audiences. It has found a good balance between the level of industrial production and the dissemination of traditional Chinese culture.
Xie Ying, general manager of Youku Drama Center, the producer of "Twelve Hours in Changan", believes that the challenge for domestic dramas to really go global is to break the inertia of themes and stories."The most important thing for domestic dramas to really go global is to explore the diversity of themes, the youth of stories and the internationalization of audio-visual language."

In the past two years, the popularity of a number of TV dramas such as "All Good", "Ice Breaking Action" and "Little Joy" has set off a creative boom in realistic themes.How to enhance the international influence of China’s realistic film and television works, let foreign audiences touch the real contemporary China, and use common values to transcend national borders to resonate will also become a new trend of "national dramas going overseas".
No matter in terms of quantity or quality, domestic TV dramas have ushered in the golden period of "going to sea". "Twelve Hours in Changan" and "Little Joy" are just the beginning. I look forward to the future batch of high-quality domestic dramas with both "Chinese stories" and "world expressions" continuing to go abroad and send out China’s cultural voice to the world.